
By now most marketers are familiar with the process of experimentation, identify a hypothesis, design a test that splits the population across one or more variants and select a winning variation based on a success metric. This “winner” has a heavy responsibility – we’re assuming that it confers the improvement in revenue and conversion that we measured during the experiment.
Is this always the case? As marketers we’re often told to look at the scientific community as the gold standard for rigorous experimental methodology. But it’s informative to take a look at where even medical testing has come up short.
For years women have been chronically underrepresented in medical trials, which disproportionately favors males in the testing population. This selection bias in medical testing extends back to pre-clinical stages – the majority of drug development research being done on male-only lab animals.
And this testing bias has had real-world consequences. A 2001 report found that 80% of the FDA-approved drugs pulled from the market for “unacceptable health risks” were found to be more harmful to women than to men. In 2013 the FDA announced revised dosing recommendations of the sleep aid Ambien, after finding that women were susceptible to risks resulting from slower metabolism of the medication.
This is a specific example of the problem of external validity in experimentation which poses a risk even if a randomized experiment is conducted appropriately and it’s possible to infer cause and effect conclusions (internal validity.) If the sampled population does not represent the broader population, then those conclusions are likely to be compromised.
Although they’re unlikely to pose a life-or-death scenario, external validity threats are very real risks to marketing experimentation. That triple digit improvement you saw within the test likely won’t produce the expected return when implemented. Ensuring test validity can be a challenging and resource intensive process, fortunately however it’s possible to decouple your return from many of these external threats entirely.
The experiments that you run have to result in better decisions, and ultimately ROI. Further down we’ll look at a situation where an external validity threat in the form of a separate campaign would have invalidated the results of a traditional A/B test. In addition, I’ll show how we were able to adjust and even exploit this external factor using a predictive optimization approach which resulted in a Customer Lifetime Value (LTV) increase of almost 70%.
Where are these threats in marketing?
Experimentation has become a core practice for experienced growth practitioners. When we review data, formulate hypotheses, and run experiments we’re trying to find a relationship between two variables in a way that can be exploited. In order to realize any meaningful return from an experiment, we must maximize its validity in at least three main ways:
- Statistical conclusion validity: Are we confident that there is a reasonable correlation between the two variables? Statistical significance calculators make this a relatively straightforward and quantifiable exercise, and this is often where marketers stop.
- Internal validity: What is the degree to which the observed correlation implies a cause and effect (causal) relationship between the two variables? This takes a bit more effort than reading a p value or confidence interval. With a well controlled environment, correlation is certainly achievable within the duration of the experiment.
- External validity: How generalizable are the conclusions from the experiment to other populations? To actually achieve the expected results from a marketing experiment we have to be able to generalize to future populations, and this is where marketers often run into problems.
A simple example of the generalizability problem is if a travel company ran an experiment in January doubling the price of travel packages to the city hosting the Super Bowl.
Due to demand, they’re likely to see a significant increase in revenue and arrive at a perfectly valid conclusion that it was caused by the price increase. If, however, they implemented that price increase permanently, they may end up causing a decrease in revenue after Super Bowl weekend as the demand for the high-priced packages to that particular city recedes.
In this example the conclusions from the sampled population during the experiment do not apply to the general. However, it’s not always easy to spot problems with generalizability In marketing since the threats related to generalizability are usually a function of time and volatility of the surrounding business context.
We sometimes think of our buyer’s context as something static and in our control, but the reality is that the context is constantly changing due to external forces. These changes can affect the validity of the conclusions we’re finding from our past and current experiments.
Here are a few examples of external circumstances that can impact our “static” buyer’s context:
- changes in your marketing campaign mix or channel distribution
- seasonality around the calendar (e.g. holidays) or industry events
- changes in product, pricing or bundling
- content & website or other experience updates
- competitor & partner announcements
- marketing trends
- changes in the business cycle or regulatory climate
Trying to generalize experiment results while the underlying context is changing can be like trying to hit a rapidly moving target. In order to accommodate this shifting context, you must take these factors into consideration in your tests and data analysis, then constantly test and re-test your assumptions.
This is pretty tedious and a lot of work however, which is why most of us don’t do it.
What if there was a way to automatically adjust and react to changing circumstances and buyer behavior?
You can’t control the future, but you can respond better to change

There’s an important difference between what scientists are doing with their experiments and what we’re trying to accomplish in marketing. There’s no way that a scientist is going to be able to reach every single potential patient in the same controlled way that they’re able to in the lab. So they’re bound by the need to generalize and extrapolate results and learnings as best they can to the general population.
In marketing, although the customer context may change, we have access to every single future customer in the same manner that we do within the experiment. If you’re running a website, email or ad A/B test, rolling it out to the rest of the population doesn’t present any significant challenges.
With a typical experiment to fully exploit the learnings you hardcode the best performing experience – which also locks in the contextual assumptions you made during the experiment . If however, you can continuously adjust for changing circumstances and deliver the most effective experience using the most recent information available then your marketing can be much more agile.
Theoretically, you could make these adjustments by continuously testing and retesting variations using only the most recent data points to inform your decision. But again, that could end up being a lot of work especially considering you might have to implement new winners in the future.
Contextual Optimization In Action
Our team at FunnelEnvy helps customers optimize web experiences for revenue. We were recently working with the team at InVision to use a predictive model to automatically decide which variation to show based on recent data.
To accomplish this we used our Predictive Revenue Optimization platform which is similar to the contextual bandit approach to optimization has that been effective at companies like Zillow, Microsoft and StitchFix. By integrating context about a site visitor along with outcomes (conversions) contextual bandits select experiences for individual visitors to maximize the probability of that outcome. Unlike traditional a/b testing or rules-based personalization they’re far more scalable, make decisions on a 1:1 basis, respond to change automatically and can incorporate multiple conversion types (e.g. down funnel or recurring revenue outcomes).
In this case we were running an experiment trying to improve their upgrade experience.
As with any freemium business model, the conversion rate from the free to paid plan is heavily scrutinized and subject to continuous testing and optimization. For InVision, the free plan has been immensely successful at familiarizing users with the product. Invision also offers a number of paid tiers with different features and price points.
During our analysis we noticed a lot of traffic from free plan users was landing on the home page. When those visitors arrived, InVision showed them a Call to Action (CTA) to “Upgrade your Plan”. When the visitor clicked on this CTA, they were taken to the page of the various premium plans, giving them the option to enter their payment information after they made a selection.
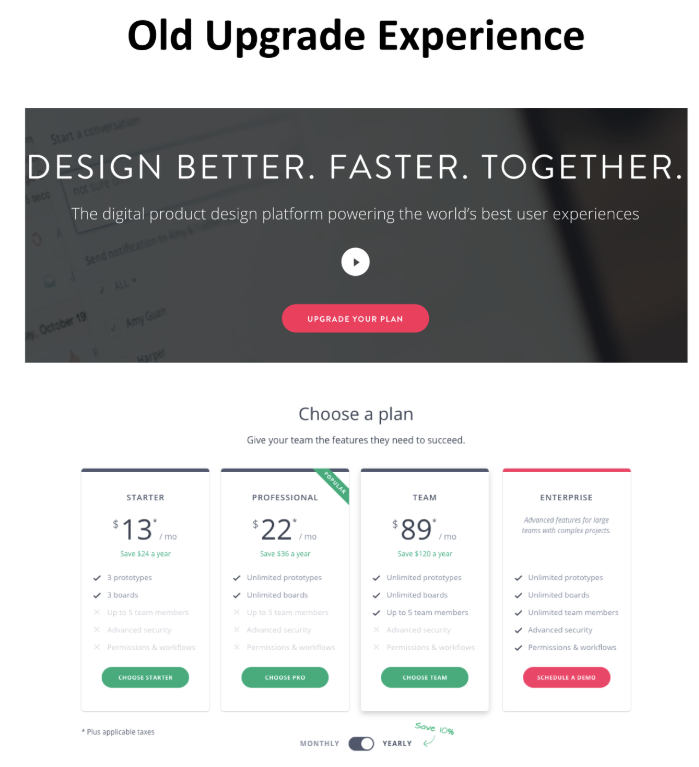
This is a relatively standard SaaS upgrade experience, and we wanted to test to find if there was any room for improvement. We noticed the the home page click through rate was relatively low, and we reasoned that simply having an “Upgrade Your Plan” CTA without a clearer articulation of the benefits that come with upgraded plans wasn’t compelling enough to get users to click.
So we came up with a hypothesis: If we present visitors with a streamlined upgrade process to the best plan for them we will see an increase in average Customer Lifetime Value from paid upgrades.
So we created three different variations of the upgrade experience, one for each of the paid plans. In each variation, we presented the visitor with the specific benefits of a plan with the upgrade price directly on the CTA. This allowed us to then skip the plan selection step and go directly into the upgrade flow (enter credit card info).
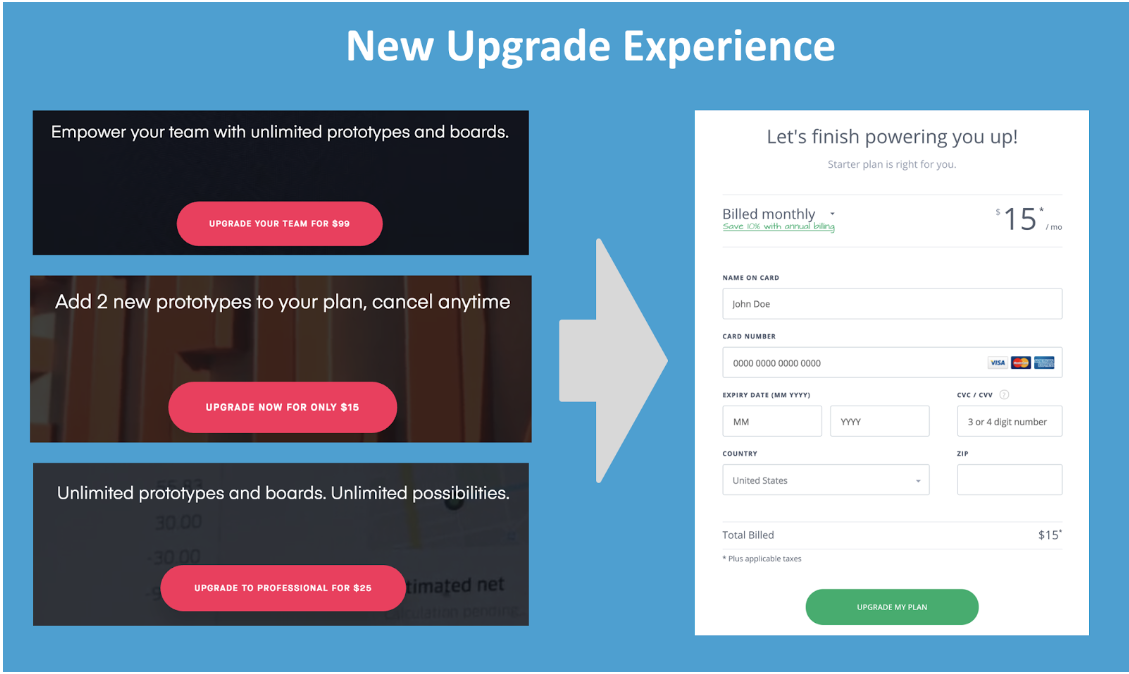
But our hypothesis says we want to show “the best plan” for each visitor. How do we go about determining that?
In this situation a single variation is unlikely to be optimal for all visitors, since free plan users are going to have different reasons for upgrading and will likely prefer different plans. So running a randomized experiment with the goal of picking a “winning” variation doesn’t make much sense.
What if instead we used context about the visitor and could show them the experience that was most likely to maximize revenue? We established this context using behavioral and firmographic data from an enrichment provider (Clearbit) and looked at as past outcomes to predict in real-time the “best” experience for each visitor. The “best” experience isn’t necessarily the one that’s most likely to convert, since each of these plans have significantly different revenue implications.
Instead, we predicted the variation that was most likely to maximize Customer Lifetime Value for each individual visitor in real-time and served that experience. Utilizing machine learning we created a rapid feedback loop to ensure our predictions were continuously improving and adapting (more on this below).
To learn how our predictive model fared we ran an experiment.
We predicted four variations (baseline and three variations) for half of the traffic (the “predicted” population) and only showed the baseline to the other half (the “holdback” population).
Results
Looking at cumulative results below we see a significant and consistent improvement in the predicted experiences over holdback. Visitors who were subject to the predicted experiences were worth 68% (p < 0.01) more on average than those that saw the control.
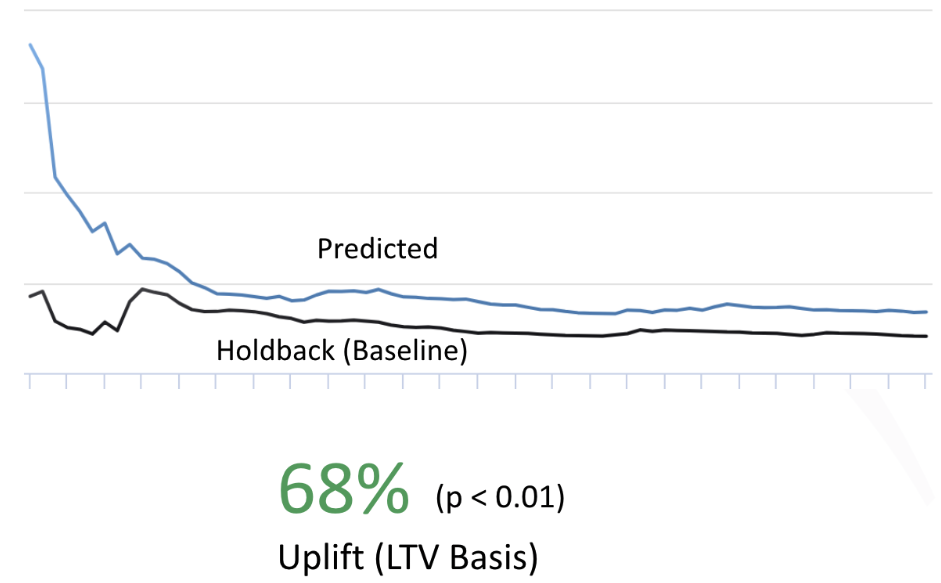
Cumulative results don’t tell the entire story however, especially in a situation like this where the underlying criteria for decisions changes as the predictive model evolves. A cumulative chart like the one above can obscure short term trends as more data points are added.
So, to better understand the campaign performance we looked at 7 day rolling averages of the value per visitor between the two populations. We also looked at the results of the four predicted experiences during the experiment.
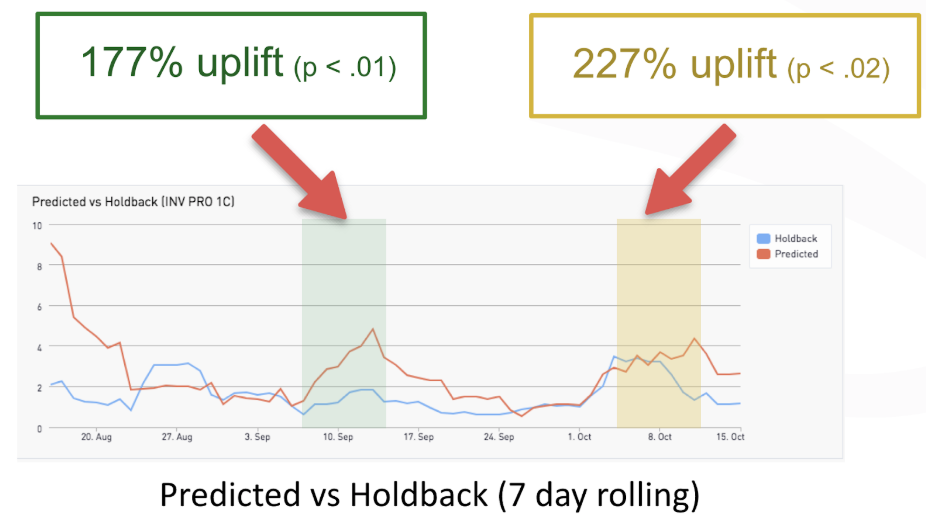
The charts above demonstrate there were several periods in which the predictive model dramatically outperformed the baseline experience. In looking at two weekly periods where we saw triple digit improvements in value per visitor over the control we also noticed the variation performance in the predicted population differed significantly.
In the first week (highlighted green) the predicted baseline variation is clearly performing the best. In the second week (highlighted yellow) the “Pro” plan variation is outperforming the others. This means that visitors’ preferences changed (in aggregate) from one plan to another.
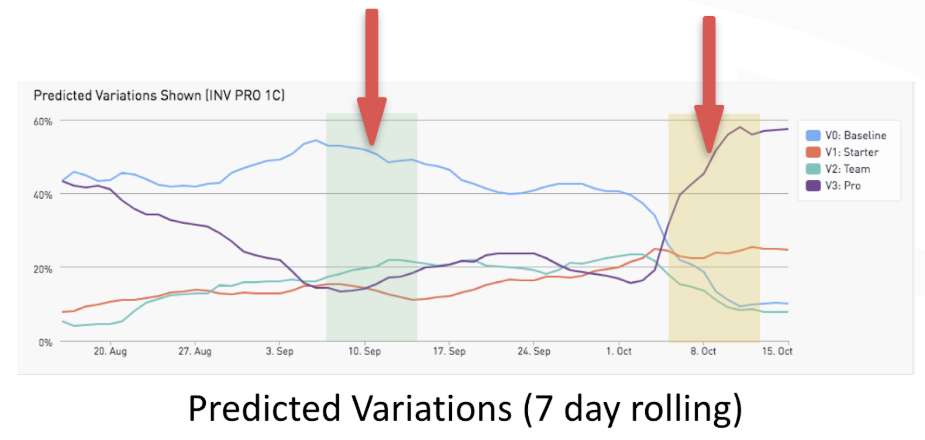
This alone shouldn’t be surprising; external circumstances can have a significant impact on the relative effectiveness of different experiences. Simply observing this effect isn’t enough to get meaningful business results, you have to be able to exploit this shift in user behavior by sending better traffic to the higher performing variation.
Using our contextual optimization model when we look at the traffic distribution over this period of time we can actually see the traffic shifting to favor the more effective experiences.
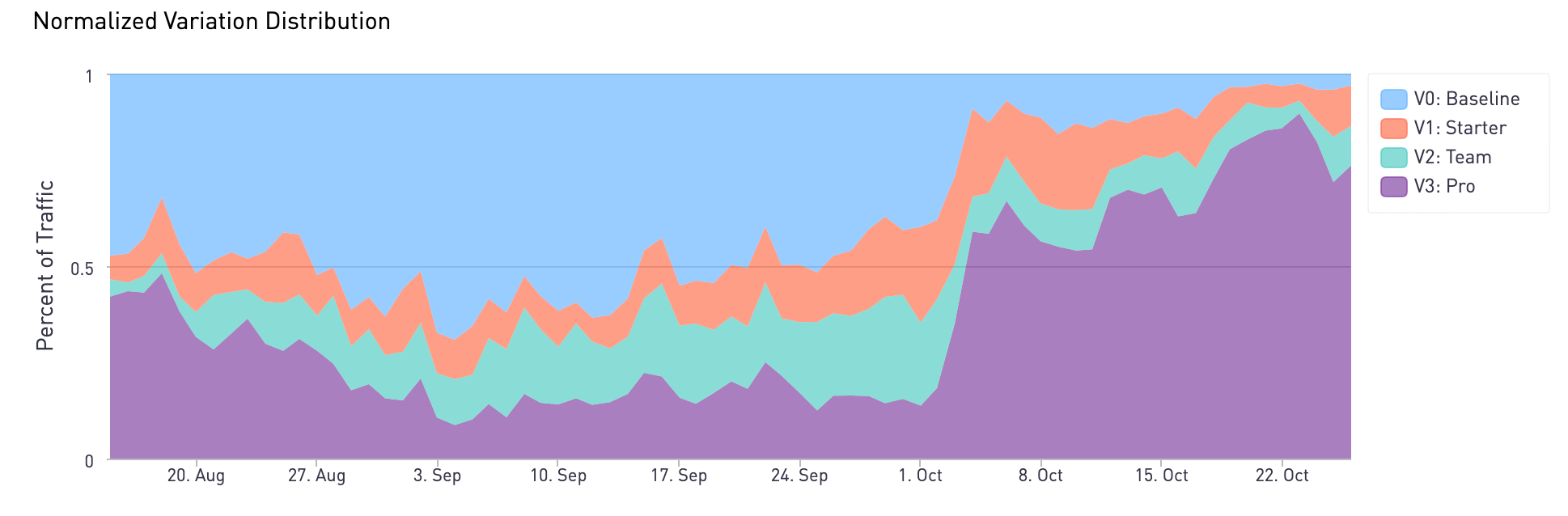
What does all this mean? At some point, circumstances changed, and a new variation started performing better. More visitors started arriving that were more likely to convert on the Pro experience, and they were served that experience more often. Using machine learning, the model was able to make that adjustment automatically based on observations and feedback from the data.
Exploiting a threat for results
It turns out that several weeks into the experiment a separate marketing campaign email went out to customers on the free tier about the Pro plan. The customers that clicked through that email and came to the site were naturally more interested in this plan and were also tagged with a campaign URL parameter.
These URL parameters are used as contextual features in the predictive model which over time learned that showing visitors with this campaign parameter the Pro plan maximized LTV.
If we had stopped the campaign to pick a “winning” variation (as you would do in a traditional experiment) we would not have picked up on this shift in behavior and likely left a significant amount of revenue on the table. The issue with generalization is that it dangerously assumes the circumstances that led to your observed results will persist in the future.
The costs associated with generalization aren’t only a function of time. In a randomized experiment, you’re trying to extrapolate (generalize) the single best experience for a population. If that population is diverse (like it is on a website home page) it’s likely that even the best performing variation for the entire population is not the most effective one for certain subgroups. Being able to target these subgroups with better experience on a 1:1 basis should be far more effective than picking a single variation.
Scientists, clinical researchers, and essentially anyone else that relies on randomized experimentation have to grapple with validity threats constantly, and have developed rigorous methods to minimize them. It’s necessary in systems that are by nature open-loop and where the risk of being wrong even once can have grave consequences.\
Marketers however have the benefit of a closed-loop system, where historical context and outcomes can be applied to decisions about future prospects, and where maximizing the aggregate outcome is generally more important than sometimes choosing the wrong experience. The faster that we can close the loop from between measurement, learning and action the more responsive the system is – and a real-time predictive model lets us do that.
It requires a degree of data integration but as we’ve seen with better use of customer context and historical outcomes, predictive optimization can be much more agile and deliver significantly higher return with less manual investment than manual experimentation approaches.



