
For the majority of marketers, when you talk about CRO and optimization programs, people immediately jump to A/B testing and assume that is the primary tactic and is the only tactic to demonstrate success for their programs and initiatives.
While A/B testing is a critical tool in your optimization program it shouldn’t be the only option on the table. While A/B testing is a valuable solution it is not a one size fits all solution for all your business challenges.
With advances in new data capabilities, marketing technologies, and real-time computing power in recent years, there are now more ways to solve for the same optimization problem.
For this discussion, we want to focus on two different techniques.
A/B test – A controlled experiment where traffic is split across 2 or more experiences and visitors are randomly assigned an experience and they stay in that experience for the duration of the test. At the end of the test, you determine a single winner based on which experience generated the best outcome for your primary KPI based on a predefined sample size/test duration and ideally reaching a specific statistically significant threshold. You then stop the test and full-scale the single winner for all traffic either directly in the testing platform or hard-coded into your CMS/platform.
Predictive Bandit – An experiment where traffic splits are not equal and where visitors are not randomly assigned. In these campaigns, a machine learning model predicts what is the best experience to serve a user either based on current + historical performance (multi-arm bandit) or based on current/historical performance + the user’s profile (contextual bandit). Like an A/B test, you can run the predicted experience vs. control to determine if a statistically significant uplift is achieved. But unlike an A/B test, the expectation with bandits is that it can run ongoing.
Now that we better understand the two techniques let’s explore reasons why both have a place in your optimization strategy.
Pros and Cons of A/B Tests
A/B testing is embraced in the analytics community as the smart and scientific way to measure the impact of change. Controlled experiments are used in testing the effectiveness of new medicines, academic/scientific studies, and of course in marketing. A/B testing is not new to marketing. It’s been done for decades in the direct mail/direct response world. And has become the recommended way to test changes on your website and mobile app assuming you can convince your stakeholders that testing is needed within your organization (it’s 2020 but still some organizations resist).
PROs:
- Quantify the impact of changes on your site. Don’t leave change to chance, measure and quantify the positive and negative impact of changes in experience with confidence.
- A/B tests are well understood in our industry. And for the most part well understood across an organization. Statistics may not be, but in general most folks understand the approach. In the end, if everything goes according to plan you have a clear outcome; either control won, or one of the challengers is declared the winner.
- Clear learnings. Related to the 2nd benefit of being well understood, benefits of an A/B testing is not just impact on business results, it’s shared learnings of what may or may not work for your site/business. With A/B tests you ideally gain a better understanding of your visitors and customers.
- At scale, you can create an organizational culture of experimentation. This change in culture leads to more creativity, risk taking, and better data driven decision making. Typically organizations that test more, make better and more informed decisions for their organization.
CONs:
- Success rates will vary, but are often low. Industry averages place the average success rate of A/B tests at 30-40%. So you have to expect that the majority of the time you are not going to end up with a new winner. Even within the winners, even fewer are high impact wins. The one hidden benefit to this, is that it makes the argument of why A/B testing is so important. If we didn’t test, the majority of the time those great ideas we think will perform better, actually perform worse or have no impact.
- One size fits all and the winner takes all. When you analyze your typical A/B test you will often see at a segment level, different groups convert very differently across the variants. At the end, you pick the variant that was best on average across all your traffic and full scale that one. But in doing so you do leave some money on the table, as the winner will not be the winner of all segments.
- Results can and do change over time. If you look at performance trends over the life of the test, it’s often the case where test results trend up and down over time. Guess what, that data reality continues to occur even after you hard code and full scale the winner. You can lock in the experience but you can’t lock in the results going forward. Results will continue to change, and a decent percentage of the time, as tests continue over time you experience a regression to the mean, where results start to flatten out. After all, if you run the same test twice, you will seldom get the same results. This is why, for many programs when you full scale that winner you usually don’t experience that lift ongoing. It still is a better way to make decisions, but as we know audiences and behaviors change. Seasonality can also be a factor.
- You sacrifice business value for concrete learnings. By design, an A/B test is designed first and foremost to generate a solid learning. Usually you are willing to sacrifice short term uplift if a variant does better than the rest, and willing to suffer through some short term downside if a variant clearly underperforms. You are willing to accept a sub optimal impact on revenue during the duration of the test because you are prioritizing a clear test result for short term business benefits.
- You need traffic. Not every organization can run A/B tests. Sufficient traffic and conversions are required to reach a statistically significant outcome. Not all sites have that, especially in B2B for example.
- Operational costs can run high. From selecting a testing platform, bringing on web developers, additional creative, and data analysis, the tool and people costs can be meaningful. Plus, there are the operational costs of introducing more time and resources to launch something, and the occasional negative costs from broken experiences or flawed tests. All marketing teams and programs incur people, tools, and operational costs, and testing is no different and often carries more cost overhead.
While I go into more detail on the cons with A/B tests, I do some because some of the cons are less understood. Still, when done right, A/B test is worth the effort and the benefits will far outweigh the cons.
But as I hopefully outlined above, A/B tests do have different strengths and weaknesses.
Pros and Cons of Predictive Bandits
Bandits have gained more popularity in marketing in recent years as computing power has advanced to the point where real-time machine learning predictions can be applied in more and more marketing technologies and for more use cases.
We have seen the trend emerge in digital advertising where bid and creative recommendations are often driven by machine learning decisions.
However, when it comes to site optimization the adoption and acceptance of bandits as a proven technique is still in the early days. For many programs, experience and maturity with these techniques are still low. Even though some of the most popular testing platforms have included those capabilities for a number of years. Let’s discuss why.
PROs:
- Bandits are by design biased toward business outcomes. Unlike A/B tests which are designed to maximize time to a clear learning. Bandits are typically designed to maximize the business outcomes at the expense of clear and precise learnings. The algorithms typically send more traffic to experiences that perform best, and route traffic away from experiences that underperform as a whole or for a specific audience segment.
- Bandits use all the data to your business advantage. In A/B tests you may use data to inform and drive your test hypothesis, but when it comes time to setup your test, you typically set it a controlled randomized experiment where traffic is split evenly and your visitors are randomly assigned to one of the variants during the duration of the test. Again, this is absolutely the right way to run a controlled experiment to generate your best chance at a concrete learning. However, this also means you are ignoring the data and trends that live within a test and the micro trends of which traits and segments perform best for each variant. With Bandits, machine learning is consuming and using all available data on the variant performance and the user to determine the best possible user experience for that user to drive the optimal business outcome. It’s far from perfect, but you are not leaving the outcome to chance. You are using all the data you know about the user and situation to make the experience decision to maximize your business outcomes.
- Bandits adjust to changing trends and behaviors. With Bandits, the intention is for it to be always on and constantly adjusting to the latest performance trends of the campaign. Unlike an A/B test where you pick one winner and lock it in, a Bandit can adjust as results change over time, and minimize any loss in performance and capitalize on any shifts in winning experiences.
- Bandits can work with less traffic. Because you are optimizing for revenue instead of learnings, you can still benefit from bandits even though you have less than optimal traffic to run a clean test.
- Bandits work well in time sensitive situations. Popular content and Black Friday sales are good examples. By the time an A/B test gives you the right answer the opportunity may have passed you by. With Bandits, it reacts in real-time to the trends and that allows you to take advantage of short term and seasonable situations.
CONs:
- Bandits are hard to interpret, understand and communicate. While A/B tests are well understood, bandits are not. The fact that decisions are controlled in real-time by a machine learning model vs. set A/B splits, means users do not have certainty about why an experience was shown or control over the traffic rotation.
- Bandits offer limited learnings. A/B tests by their design as controlled experiments are designed to produce learnings. Bandits will typically sacrifice clarity of learnings when it comes to which experience works best. You can often be informed about what segment or what feature influenced the bandit model decision, but it’s not as clear cut on what is the final absolute winner. Often you are A/B testing the technique, do bandits outperform control or an A/B test for this page/site. But with bandits it’s harder to generate clear learnings on winning experiences. In the end you are optimizing for revenue and other business outcomes at the expense of a clear isolated learning. As an organization you need to be aware and accept this reality and your stakeholders need to accept this reality too.
- Bandits can provide an inconsistent user experience. As we called out earlier, to maximize business outcomes, bandits by design do not make experiences sticky to the user, and will often serve a different experience to the same user if the data suggests it will result in a better outcome. While this maximizes revenue, it can lead to experiences being more dynamic and changing for a given user. While dynamic websites are generally considered a positive, because it is not very common in 2020 (surprisingly), this dynamic approach to site experience can be a drawback for some users.
- Bandits require more thoughtfulness on experience design. While you can A/B test most things from layout, to copy, to color, to offers, the same isn’t always true for predictive bandits. Bandits work best where you have varied user intent and ideally varied offers and outcomes. Bandits are more effective if they can predict for more outcomes for a larger range of user intent. If you are running CTA color and size changes you are better off running a traditional A/B test. There is likely less signal in the data in terms of user preference of a button color/design and the results will likely hold true on average for most users. That is why bandits work better when intent varies across the visitors and potential offers displayed can also vary.
When to Use A/B Tests and When to Use Predictive Bandits
Now that you know the PROs and Cons for A/B tests and predictive bandits let’s talk about some practical applications of each and when you should one over the other.
When A/B Tests are Recommended
- When you need a clear learning and more certainty on the final decision. Examples here would be a pricing or homepage test.
- When you want to lock in a specific design or experience for all. Examples here are things like a new homepage design, a new form layout, or say our site wide CTA treatments. Here there is more operational value in locking in that specific winner and then optimizing further on that.
- When intent and offer options are narrow in scope. When intent for all users is similar the offer is the same for all, then A/B testing usually works better than predictive bandits. An example would be optimizing for the final cart checkout page. Everyone there is ordering (or not) and the offer is a checkout (or not).
When Predictive Bandits are Recommended
- When you want to maximize revenue. If you have aggressive revenue goals then bandits are a better tactic to get you there as you are using all the data available to make the optimal revenue decision. A good example here is presenting the right offer on a homepage hero or promoting a specific price/package on the pricing page. In those situations, the general site is the same but you are predicting the best offer and experience to spotlight to maximize revenue.
- When intent and offer options vary broadly. Predictions work better when there’s a wider range of users and intent and a wider range of offers and outcomes to present. This is where the value of machine learning and crunching dozens and hundreds of data attributes in real-time is helpful. Good examples here can be homepage, brand landing pages, and pricing/plan pages. In these scenarios intent and options/offers presented can vary.
Now that you know the strengths and benefits of both tactics I think you will agree that both tactics should be part of your optimization and personalization toolkit.
Running A/B Testing and Predictive Campaigns in FunnelEnvy
With the FunnelEnvy platform we give you the ability to run both A/B and predictive campaigns and apply the right tool for the job. Unlike other platforms, both tactics are available as part of our standard license.
To get started you just create a new campaign and then select the preferred template option between Predictive and A/B testing.
If you selected an A/B testing then the “Campaign Decision” section will default the settings typical of an A/B test.
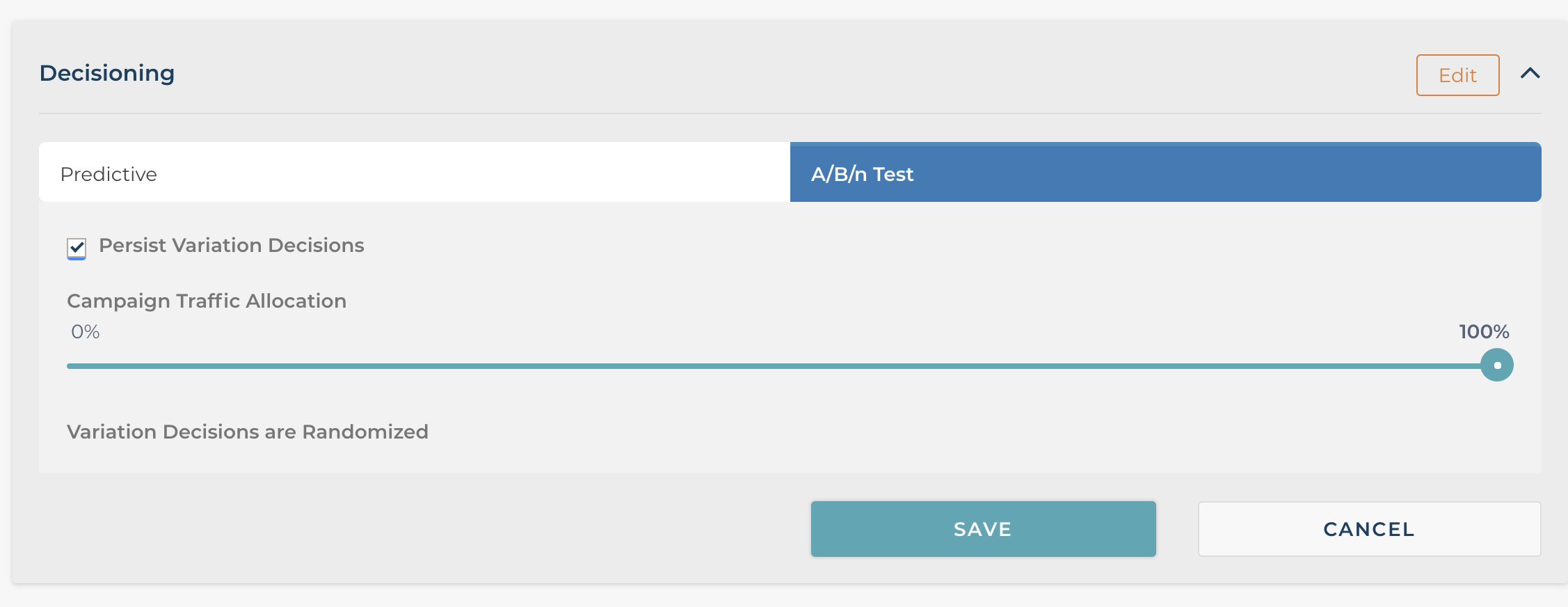
As you can see A/B testing is the decision type defaulted, and the “Persistence Variations Decisions” feature is checked so the same experience is served to the user across sessions. Lastly, you can adjust the traffic allocation to determine what percentage of traffic enters into the test. By default and typically it’s set to 100%.
If you were to select a Predictive campaign template, the decision type would instead default to Predictive as seen in the screen below.
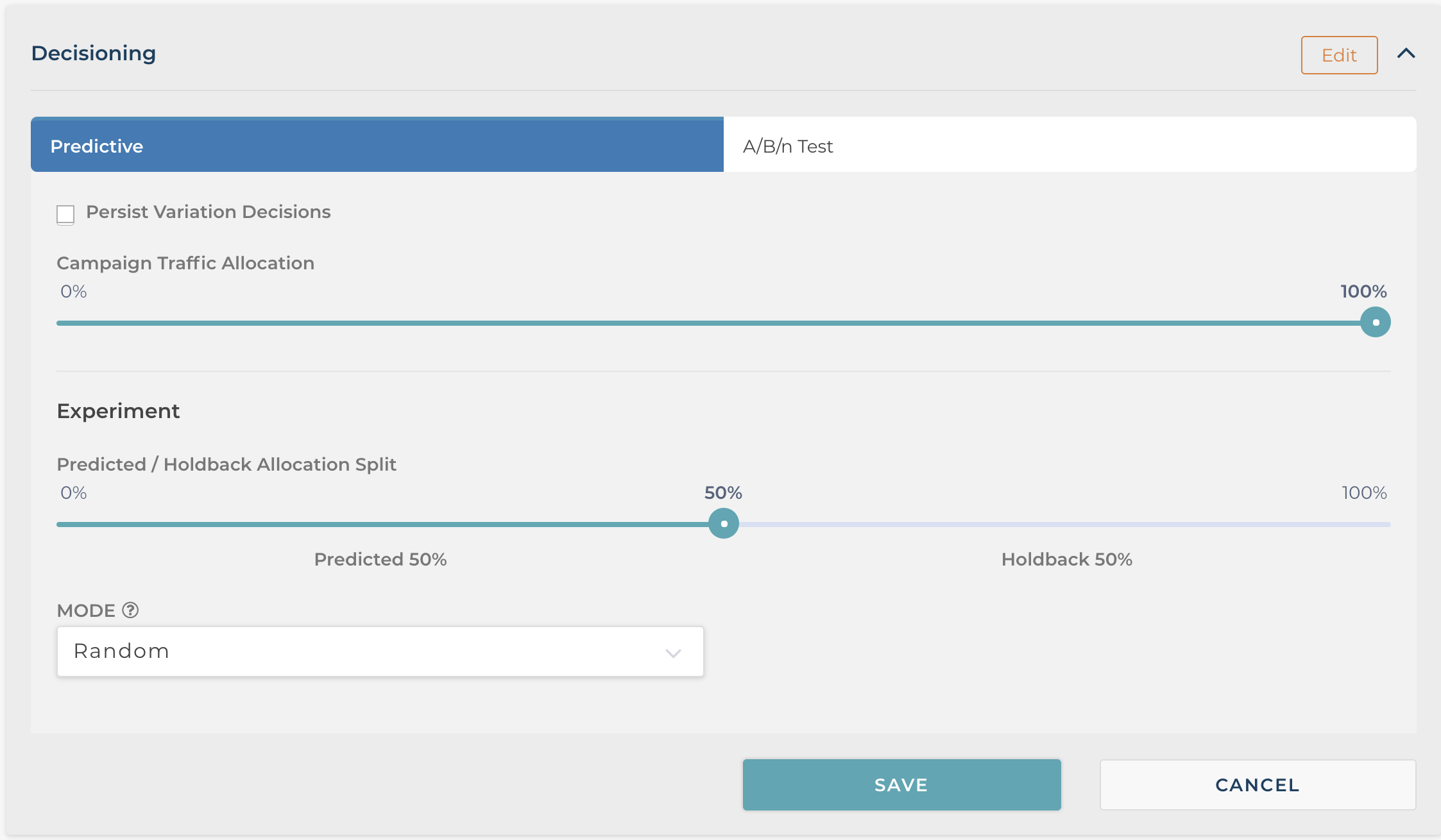
In addition, the “Persist Variation Decisions” feature is not selected by default. As mentioned earlier, we typically see improved revenue performance when the campaign can rotate different offers over time to the same user. That makes sense, as a user may not respond to an initial offer, but maybe convert when presented another. But we do recognize their legitimate reasons to also make predictive decisions sticky, especially when running in locations like your pricing and plans page. And like with the A/B template, you also can set traffic allocation from 0-100%.
What is specific to Predictive campaigns is the predictive experiment options. Here you have two choices to make. The first choice is what percentage of traffic should be included in the predicted group vs holdback. The experiment section is where you can test the incremental value of a predictive campaign by holding back a portion of your traffic as the control.
In the screen below we have set the holdback to 50%. This will result in 50% of the traffic being assigned to the predictive experience and the remaining 50% gets served a control. This allows you to test the incremental value of running a predictive campaign on your site.
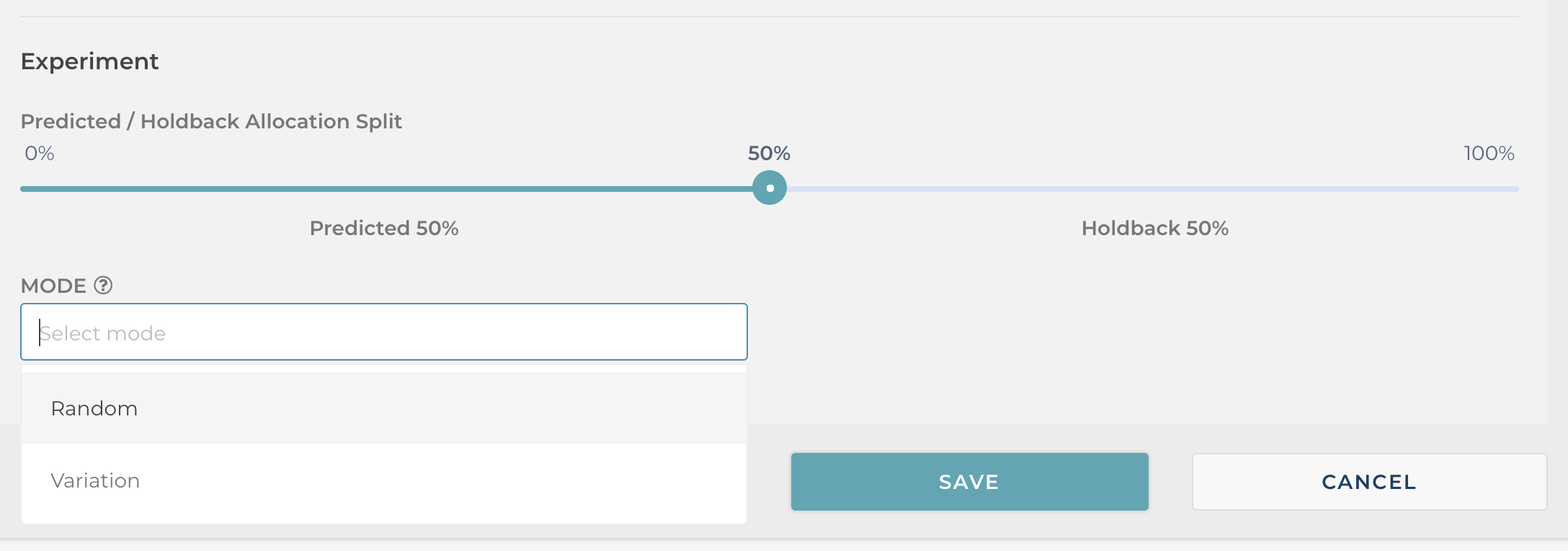
Typically, we recommend the client start a new campaign as a 50/50 campaign and as they see the predictive campaign outperform the control we then recommend full scaling the predictive campaign to 100%.
The second option you have with a predictive campaign is to determine the composition of your holdback group. You can choose between assigning the variation a specific variation, like baseline control, or you can set holdback to random in which case the holdback will run as an A/B test for that traffic across all the available variants. The “Random” option is useful if you want to determine the incremental uplift in running a predictive campaign vs. an A/B test.
As you can see, our predictive campaign setup still allows you to isolate and measure the incremental impact of a predictive bandit approach by running it as a controlled experiment.
Our typical client will often run both types of campaigns simultaneously on different areas of their site and targeted for different audiences. Rather than having to choose one tactic or another, FunnelEnvy clients have the best of both worlds.
Getting Started
As you can see, A/B testing and predictive bandits are both valuable tactics in your optimization/personalization programs. Like any tactic you need to pick the right tool for the job.
If you’re not yet using FunnelEnvy but are interested in personalizing your website using a combination of A/B tests and predictive campaigns we’d love to hear from you! You can contact us here: https://www.funnelenvy.com/contact/



